基于DevOps平台构建自己博客:5-Coding平台提供的能力介绍
一、Coding平台简介

这就是coding平台的官方首页,访问后我们可以很清楚的看到该平台所提供的核心能力,正如描述的一样:提供一站式开发协作工具,帮助研发团队快速落地敏捷开发与DevOps开发方式,实现研发效能升级。
但是,这里Simon要提醒一下大家,目前这个平台还不是一个完整的DevOps平台。不过,可能平台后续会增加该部分能力,但截止当前文章编写,并没有看到目前有这个迹象。具体DevOps的相关知识,可以参考一下我们上一章讲的内容:基于DevOps平台构建自己博客:4-DevOps入门介绍
二、Coding平台能力介绍
下面我们看下这个平台具体的能力:

通过二级菜单,我们可以看到该平台提供了代码托管、持续集成、制品库、持续部署、项目协同、测试管理、API文档管理。我们现在详细说下这几部分的功能分别对应DevOps的哪些环节。
代码托管
在DevOps中,我们的代码是需要存储在代码库中的,设计人员或开发人员在代码库初始化项目工程后,需要将代码仓库的代码拉取到本地进行开发,并在开发结束后提交到代码仓库。而代码仓库需要提供如版本控制、提交管理、分支管理、Tag管理、合并管理、冲突解决、分支保护等等一系列的功能。常用代码仓库有subversion、git及mercurial等,具体可以参考Wiki:Codebase
在国内常用的解决方案中,我们会选用Gitlab,Github或者Gitee。当然,某些大厂也会有自己的仓库系统,如阿里的云效,腾讯的Coding。虽然,他们来着不同的公司,但是提供的能力几乎都是一样的。那么,代码托管具体有什么作用和意义呢?
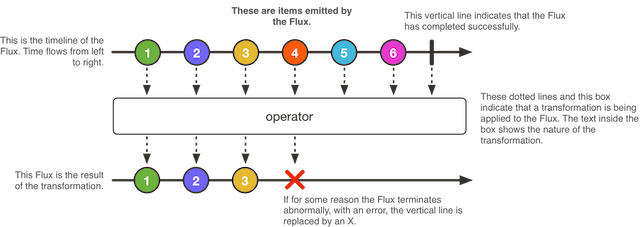
对于多人协同开发而言,一个系统会有多人甚至多个团队共同完成,在开发过程中涉及到大量代码同步合并的工作,如果仅仅靠开发人员之间手动同步本地代码根本无法完成,而且极易出现人为的代码丢失、覆盖等问题。代码仓库在最早的多人协同开发中就体现出其重要的价值与地位。随着软件系统的不段更新,团队人员的更迭,代码仓库中的代码也成为了软件公司最重要、最直接的资产。与此同时,软件的升级所依赖的最终要的概念——版本,也就孕育而生。版本体现在交付的软件的标签,也同样需要体现在代码管理之中,所以,代码仓库的版本管理功能也便是最基本的能力。代码仓库支持版本管理之后,我们的软件开发组织变可以继续裂变成多个,针对不同的版本做开发、问题修复。在敏捷开发中,我们会发现敏捷团队会以故事为单位进行任务分配,这个时候,每个开发人员会有多个故事,但是,仅仅依靠版本的功能根本无法区分和管理到每个任务,这时,我们需要引入一个新的概念,那就是——分支(branch)。分支很好的解决了开发过程中,细粒度的代码管理问题。基于分支管理,在配合我们的研发流程中代码管理规范,一套完整且好用的解决方案就孕育而生了。而这套方案可以更好的支撑敏捷团队、支撑微服务、支撑DevOps。如下是我在管理团队时使用的代码分支管理流程:
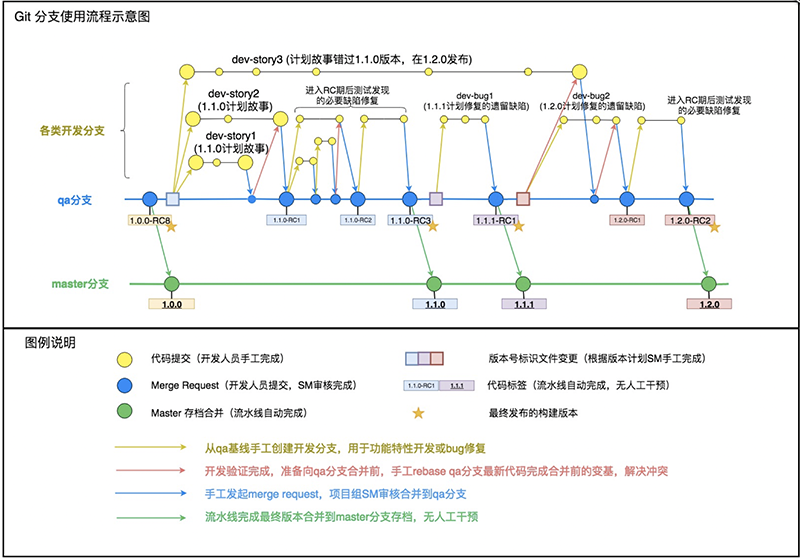
这里就不再过多的说明代码管理的内容,有兴趣的可以留言,后续我会准备专题来讲解该部分内容。
说了这么多,代码托管在DevOps中具体有什么用呢?总结一下有以下几点:
- 存储并集合了所有开发人员可被编译部署的代码。
- 存储所有提交代码的分支、标签及提交记录等信息。
- 提供了代码分支管理及分支保护的功能,防止代码被非正常覆盖。
- 提供其他组件的安全拉取代码的源文件,可作为后续持续编译、持续部署的基础。
- 作为DevOps中,产出交付物的唯一源使用。
持续集成
英语:Continuous integration,缩写为CI,持续集成的能力在当前的软件开发过程中愈发重要。在早期的软件开发过程当中,很多公司有独立的团队来做这部分工作,主要内容就是合并开发提交到某个分支的代码,一个团队一个分支,团队内所有开发人员共用这个分支。多个开发团队的分支代码统一由这个组来合并到产品的主干分支上,解决冲突,然后手动编译、打包、部署到测试环境、执行各种测试、生成版本的升级包。最后发给用户或者一线运维人员。如果在测试过程中,出现了问题,则需重复合并代码到部署的动作,如果涉及到多个环境,工作量又增加。而持续集成解决了前半部分的工作:
- 手动的编译动作由系统自动触发。
- 打包的动作由系统自动触发。
- 在部署前的静态代码检查可由系统自动触发。
- 在部署前的单元测试可由系统自动触发。
- 在部署后的自动化测试可由系统自动触发。
而上面所说的系统就是我们DevOps中的持续集成的部分。在目前的行业内,通用的解决方案大多采用Jenkins作为整个DevOps流水线的核心来使用。下图是一张Jenkins的工作界面:
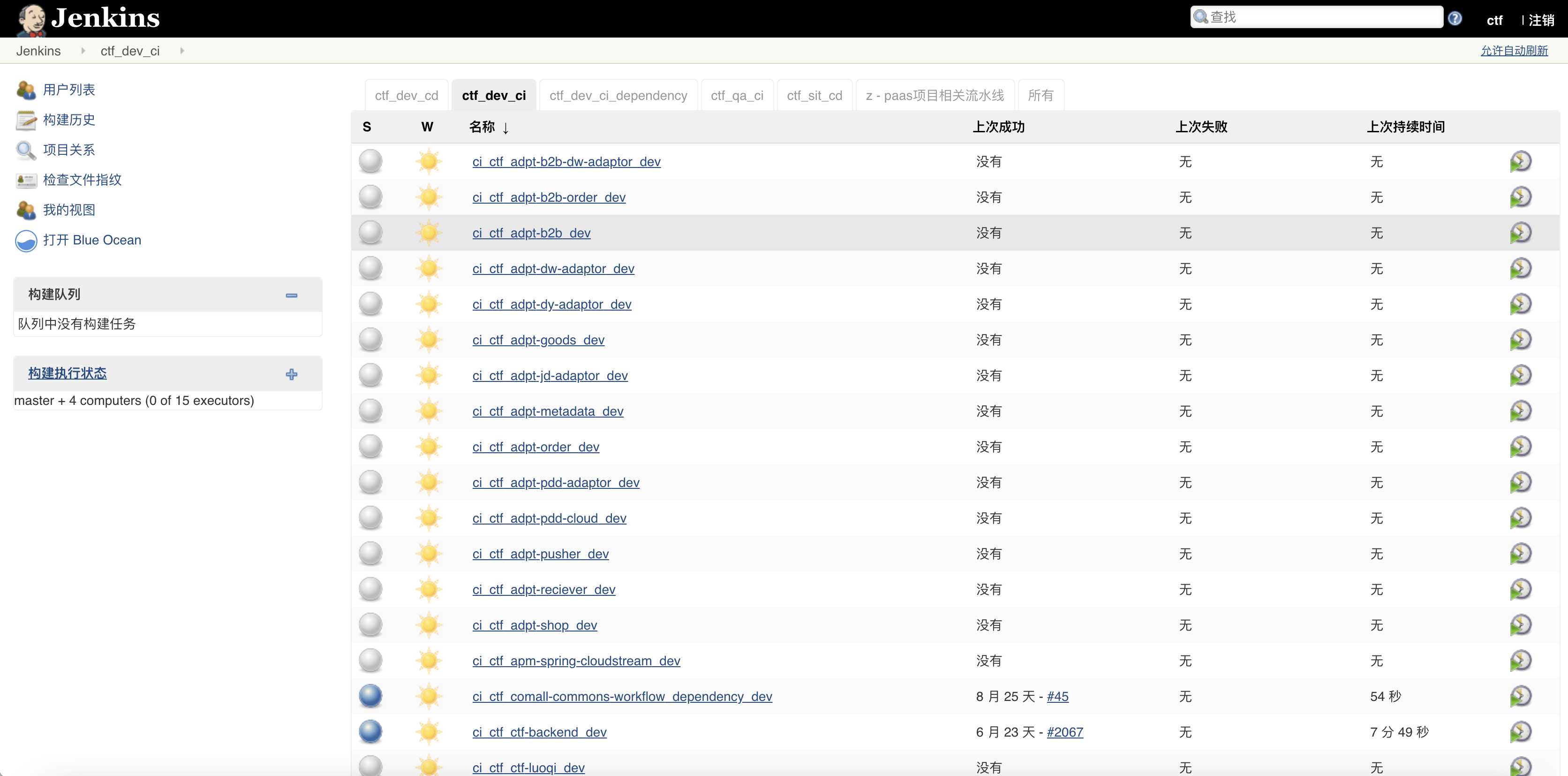
我们通常将持续集成简称为CI。而持续集成工具为我们提供了可定制化的操作能力,以Jenkins为例:
- 可以在这个平台配置对应的代码仓库,作为待编译代码的源
- 可以预设设定系统参数和变量。
- 可以在流水线中定义需要执行的各个阶段
- 可以在流水线中每个阶段书写我们需要执行的脚本
- 可以手动触发每个流水线的执行
- 可以查看执行过程中的日志
- 如果脚本中涉及拉取代码,可以将拉取的代码在本地的沙箱中编译
- 可以集成如sonar等工具,执行静态代码检查
类似Jenkins这种工具,为我们在持续集成中提供了几乎无限的可能。因为他是可扩展,他的核心能力取决于我们的流水线编排及具体脚本的书写。而当前的Coding平台的持续集成能力,为我们提供了更为简单易用且兼容Jenkinsfile语法的功能。当然,就目前了解到各大厂的解决方案中,基本持续基础的能来只是在Jenkins上封装了一层,增加了图形界面及配置的易用性,底层使用的仍然是Jenkins。具体可以参考官方的产品说明:https://coding.net/products/ci

制品库
制品是持续集成(CI)的产物,而制品库就是存放这些产物的仓库。那为什么要有制品库呢?持续集成后,直接将生成的制品部署到环境上不就可以了嘛,有必要单独存放到仓库吗?其实制品库的存在,有其重要的意义:
1. 制品库为持续集成产物提供了公共的存放位置,将持续集成和持续部署的流程解耦,使持续部署不再强依赖于持续集成,转而是依赖制品库中的制品。这样就为一次编译,任意部署提供了前提。
2. 制品库也有版本管理,每次持续集成生成的制品都可以作为版本存储在仓库中,至于每个版本如何使用,则由管理人员自己决定。当然,如果需要检查制品是否有问题,也可以从仓库下载制品分析,为问题定位分析提供了一种途径。
3. 制品仓库的出现将原来以流程为交付标准的情况,转变为以制品作为交付标准。进而保证了研发流程中,对交付物(制品)的全流程质量保证和质检目标的全程一致性。
持续部署
英语:Continuous deployment,缩写为CD,意指在软件开发流程中,以自动化方式,频繁而且持续性的,将软件部署到生产环境(production environment)中,使软件产品能够快速的发展。在概念中我们提到以自动化方式、频繁和持续性这些,那这些词在具体的DevOps中是如何体现的呢?通常情况,持续部署与持续集成结合,其他的工具或方式,使得持续部署可以自动触发,而触发后,部署物则是由持续集成构建出来的制品,而该制品在本构建之后便存放于制品库,持续部署则根据不同的场景,不同的环境,通过主动获取或发送指令到目标环境的方式,使得制品被部署到指定环境。而触发这一些列的动作,上面说到工具或方法,不同的解决方案有不同的方式。但是,自动化触发场景下,大多基于研发人员提交commit来处理,也就是代码仓库提供的钩子或者是用一些工具,如argocd。具体这里不做其他的延伸,有兴趣的小伙伴可以自行研究或留言讨论。
三、DevOps中的Ops
至此,我们已经介绍了一大半的DevOps的能力,但是,这部分主要集中在研发的阶段及一部分的Ops,所以说,Coding平台提供的DevOps的解决方案,目前还只是关注到研发及部署这一块,即DevOps的Dev这部分,而Ops就仅仅涉及到一部分,那么在DevOps中,Ops具体包含哪些内容呢?
DevOps是Development和Operations的组合词,所以,Ops自然就是Operations,即运维。不知道大家是否还记得上一讲:4-DevOps入门介绍中有这么一张图:
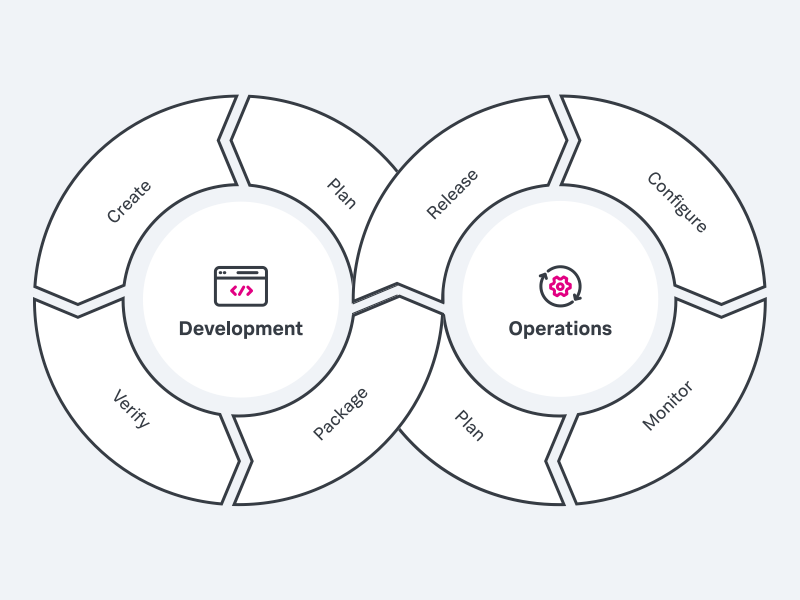
这里面与Ops相关的部分可以看做从Release就开始了,然后就是configure, Monitor以及Plan并进入下次Development循环。在Operations的循环中,Release的便是我们上面提到的制品,而configure的就是针对不同的环境,拥有不同的配置。在上面的持续部署中,我们并没有提到。但是,在生产实践当中,不同环境不同配置是持续部署阶段的重要部分。因为配置可以针对环境区分,也使得不同环境的差异性得以体现。而这种不同配置,通常我们的处理方式就是使用一个配置仓库,每个环境在配置仓库对应了一个标签,如PROD, UAT, SIT, DEV等等,而每个标签对应了一组配置文件集合。这样就可以针对不同环境使用不同的配置,不同的配置引用不同的中间件等资源。
除了上面说到的Configure,目前Coding平台以及其他市面上类似的解决方案缺失的主要是Monitor这部分。Monitor的价值在运维阶段至关重要,而在大量使用微服务及容器化方案的当下,传统的Monitor方式则变的愈发的困难。加上DevOps的特性,旧的制品是可能随时被替换的,相应的本地日志(包括应用日志、资源信息、容器信息等等)也会随着容器的销毁和重建而消失。同时,在微服务场景下,大量的微服务如果采用传统的监控方式,也会有大量的工作量。
目前业界常用的解决方案如ELK + Prometheus + Grafanar,这一套的好处就是好用且免费。借用一张filebeats的图片:
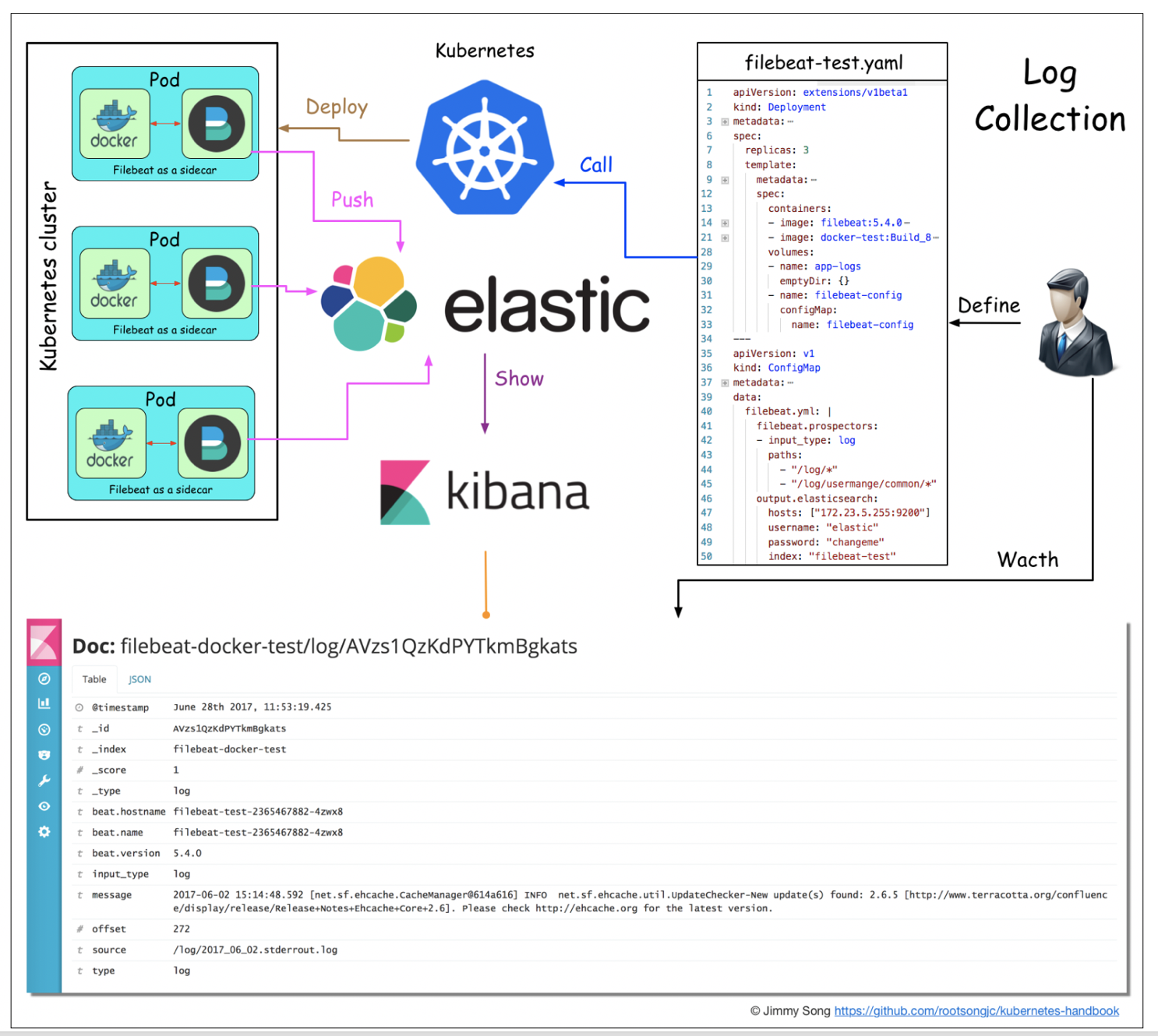
上图描述了日志收集及检索的部分,而Prometheus主要是收集资源信息,Grafana是展示平台。关于Monitor部分,不是本系列的重点,这里只是略微的提一下,有兴趣的朋友可以自己学习一下,或者留言交流。
至此,Coding平台的能力也基本介绍的差不多了,我们也提供了一些行业内的实现作为参考,如果有什么问题欢迎留言,谢谢!
- 本文标签: Coding DevOps
- 本文链接: https://www.v8en.com/article/7
- 版权声明: 本文由SIMON原创发布,转载请遵循《署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)》许可协议授权